这篇文章上次修改于 439 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
数据集
- 我们使用pytorch提供的CIFAR10作为本次模型的训练集和测试集
模型构建
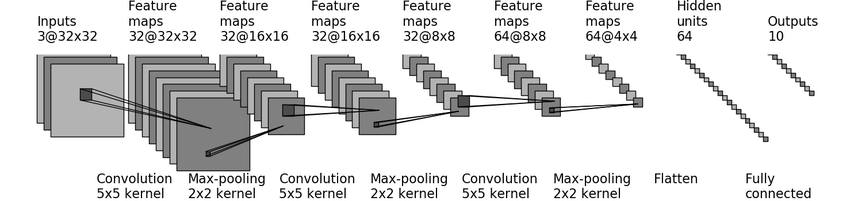
根据上图构建我们的神经网络模型
模型代码
- 我们创建一个model_demo.py的文件,将下面的代码写入文件
#导入神经网络nn
from torch import nn
#导入卷积,池化,线性方法
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
#定义模型娇ModelDemo
class ModelDemo(nn.Module):
def __init__(self):
super(ModelDemo, self).__init__()
# 参考上图的网络结构,加入训练方法到Sequential
self.model = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
编写模型训练代码
- 我们创建一个model_train.py的文件,将下面的代码写入文件
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import model_demo
import torch
#设置数据集
trainDataSet = torchvision.datasets.CIFAR10(root="./dataset", transform=torchvision.transforms.ToTensor(), train=True, download=True)
testDataSet = torchvision.datasets.CIFAR10(root="./dataset", transform=torchvision.transforms.ToTensor(), train=False, download=True)
#load数据集
trainDataLoad = DataLoader(trainDataSet, 64)
testDataLoad = DataLoader(testDataSet, 64)
trainDataLen = len(trainDataSet)
testDataLen = len(testDataSet)
#设置训练设备 默认使用cpu训练,如果发现有gpu则使用gpu作为训练设备
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
# 定义自己的网络模型
seqDemo = model_demo.ModelDemo()
# 指定使用训练设备
seqDemo.to(device)
# 设置损失函数
loss = nn.CrossEntropyLoss()
loss.to(device)
# 学习速率 0.01
learningRate = 1e-2
# 优化器
optim = torch.optim.SGD(seqDemo.parameters(), lr=learningRate)
#训练轮数
epoch = 50
#总训练次数
totalTrain = 0
#使用tensorboard 显示一下loss和正确率
writer = SummaryWriter("logs_train")
for i in range(epoch):
# 开始训练
seqDemo.train()
print("===========开始第{}轮训练===========".format(i+1))
totalTrainLoss = 0
# 循环训练集获取训练数据和标签
for data in trainDataLoad:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = seqDemo(imgs)
# 计算损失
resLoss = loss(output, targets)
# 优化器grad置0
optim.zero_grad()
# 反向传播优化
resLoss.backward(resLoss)
# 优化器优化
optim.step()
# 累计训练次数
totalTrain += 1
totalTrainLoss += resLoss.item()
if totalTrain % 100 == 0:
print("训练次数:{}, loss:{}".format(totalTrain, resLoss.item()))
writer.add_scalar("train_loss", resLoss, totalTrain)
# 开始测试上一轮的模型
seqDemo.eval()
totalTestLoss = 0
totalAccuracy = 0
with torch.no_grad():
# 循环测试集获取测试数据和标签
for data in testDataLoad:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = seqDemo(imgs)
resLoss = loss(output, targets)
totalTestLoss = totalTestLoss + resLoss.item()
accuracy = (output.argmax(1) == targets).sum()
totalAccuracy += accuracy
print("整体测试集上的Loss:{}".format(totalTestLoss))
print("整体测试集上的正确率:{}".format(totalAccuracy/testDataLen))
writer.add_scalar("test_loss", totalTestLoss, i)
writer.add_scalar("test_accuracy", totalAccuracy/testDataLen, i)
#每训练十轮保存一次模型 或者是 最后一轮保存模型
if (i+1) % 10 == 0 or (i+1) == epoch:
torch.save(seqDemo, "demoModel{}.pth".format(i+1))
torch.save(seqDemo, "demoModel{}.pth".format(i+1))
# 下面是另外一种保存模型的方式
#torch.save(seqDemo.state_dict(), "demoModel{}.pth".format(i+1))
writer.close()
训练模型
- 我们可以在自己的本地电脑执行代码进行模型训练
- 也可以使用 https://colab.research.google.com/ 来进行模型训练,本次我们使用google的colab来进行训练
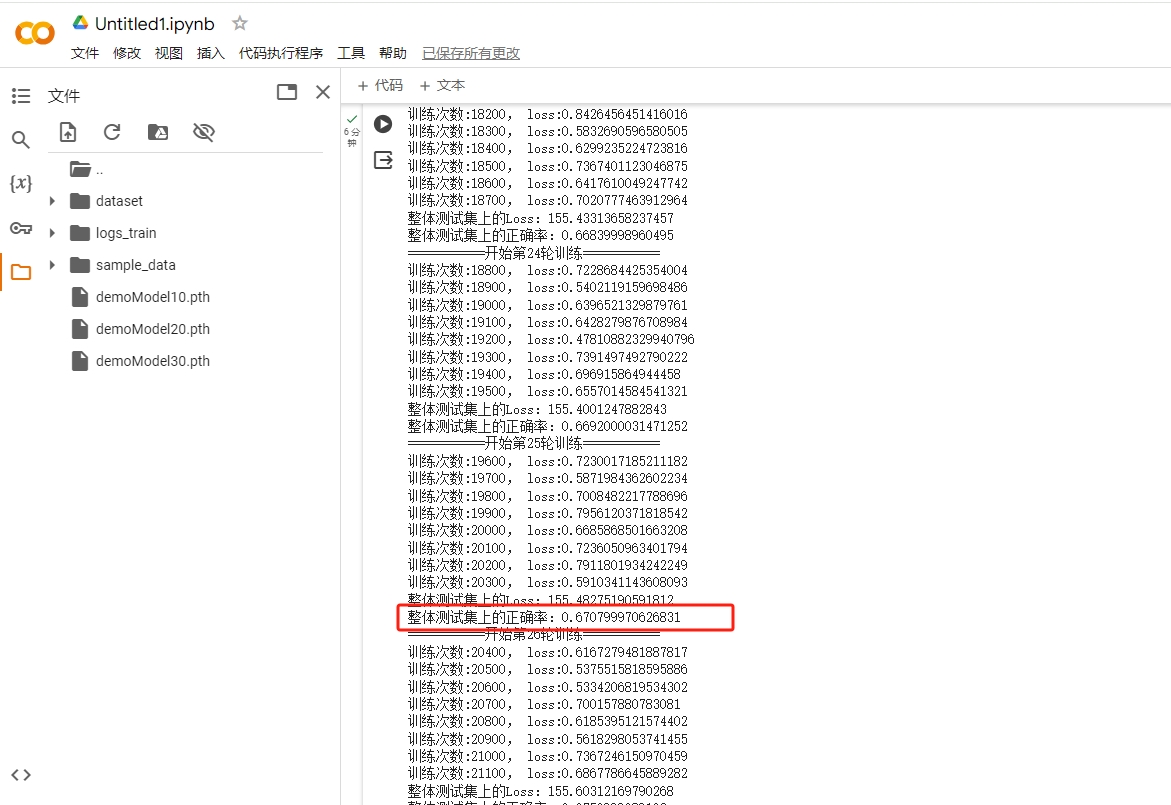
可以看到在训练25轮的时候,正确率已经达到67%了
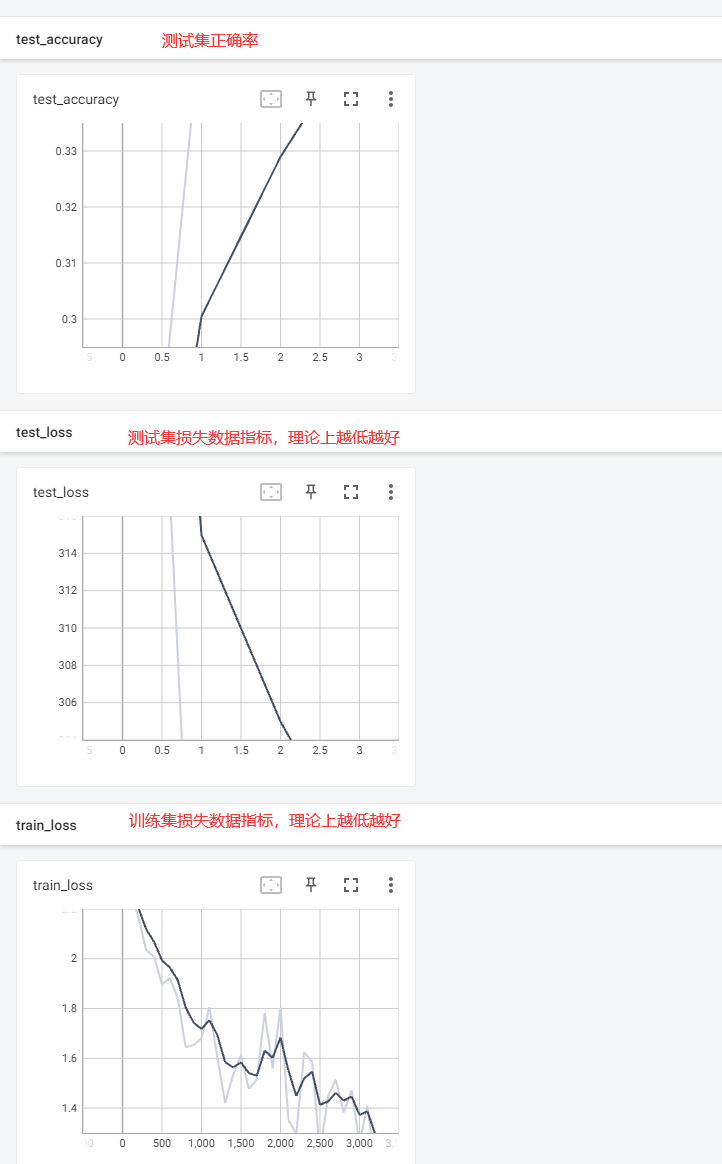
使用tensorboard 直观的看一下loss和正确率数据
- 在命令行执行下面的命令, 打开tensorboard 服务
tensorboard --logdir="logs_train"
出现下图信息,说明启动成功

- 浏览器打开地址: http://localhost:6006/,页面如下图
没有评论
博主关闭了评论...